Traditionally a single program would have multiple capabilities. When we scale that program, it would be replicating those bundles of capabilities. Microservices Architecture improves this by breaking the capabilities into individual programs. Each of these programs would run in its own container and therefore, when scaled, its much easier to pick and choose which capabilities are to the be replicated.
Some consider “Microservices” as SOA. In other words Microservices is a subset under SOA. However the contrasting view considers SOA a more of an ESB (Enterprise Service Bus) whereas Microservices is more specific to the capabilities.
A challenge with defining Microservices is how big is a service? For example, would the business function of Payroll be a service? This may depend on the situation and enterprise.
Below are some of the characteristics of Microservices (as defined by Martin Fowler).
Components
Some terminology – these “programs” are sometimes referred to as components. A component = something that can be independently replaceable and upgradeable. It could be as small as an object, but generally it is considered a combination of some libraries and services.
Capabilities
Generally when looking at an enterprise we see teams broken down by their technologies, for example UI/UX, DBA, Server Admins, Network, etc. The Microservice Architecture encourages changing these teams to be by Business Functions, such as Shipping, PO, etc. This way the ‘capabilities’ are more functional based instead of technologies. With this approach is very easy to support multiple platforms and technologies.
Products
Microservices are grouped by products and not projects. Similar to the Capabilities definition above, the focus is on the end product or capability. A project can encapsulate multiple capabilities that generate multiple products. Therefore the focus needs to be on the end product. This leads to smart endpoints.
Smart Endpoints
Emphasis on smart endpoints. The infrastructure just provides the routing/piping to these endpoints and the main capabilities are found on the endpoints, organized carefully so that it clearly shows what capability it is supporting.
Decentralization
As microservices focus on the end products it naturally decentralizes traditional processes focused on keeping groups or all capabilities. A disadvantage of decentralization is that it creates a challenge in inter-modulation. Since everything is separated by capabilities, it enforces strict independence and decoupling, which can be problematic in tightly related systems.
Automation
One of the benefits of Microservices is the flexibility and speed of deployment. This is easily implemented by using automated processes and tools, such as continuous integration and deployment.
Microservices Architectures
Many of the following text was copied from the book “Microservices Architecture for Containerized Applications” by Microsoft.
Some more formal definitions when trying to architect microservices. A service is from SOA where a single functionality is exposed to one or many clients and accessible over different mediums (such as the Internet). Having an SOA gives reuse-ability as the same functionality can be used for multiple clients. Also services are stateless as it can be accessed at anytime from any client. A microservice is subset of service that adds some design principals to how a service should be organized. It enhances the SOA by giving scalability, flexibility and increased performance. It’s focus is to decompose the monolithic service into small lightweight services. Sometimes each microservice can have its own datastore. A user’s transaction would flow through many microservices.
Service-oriented architecture (SOA) was an overused term and has meant different things to different people. But as a common denominator, SOA means that you structure your application by decomposing it into multiple services (most commonly as HTTP services) that can be classified as different types like subsystems or tiers.
Those services can now be deployed as Docker containers, which solves deployment issues, because all the dependencies are included in the container image. However, when you need to scale up SOA applications, you might have scalability and availability challenges if you are deploying based on single Docker hosts. Docker containers are useful (but not required) for both traditional service-oriented architectures and the more advanced microservices architectures.
Microservices derive from SOA, but SOA is different from microservices architecture. Features like big central brokers, central orchestrators at the organization level, and the Enterprise Service Bus (ESB) are typical in SOA. But in most cases, these are anti-patterns in the microservice community. In fact, some people argue that “The microservice architecture is SOA done right.”
The microservice architecture enables Domain-Driven Design patterns by allowing specific functions to run in their independent containers. The container model states that an image instance represents a single process. Even for monolithic applications, the whole application would reside in a single container as a single process on the host. Some benefits of running monolithic applications in a container are:
- Easier deployment / development with dependencies all contained in container
- Scalability – easier to scale containers than servers or vm
- Easier to apply updates – updating docker images are far easier than updating servers
- Ability to break monolithic application into functions – its easy to break out or build out functionality into new containers
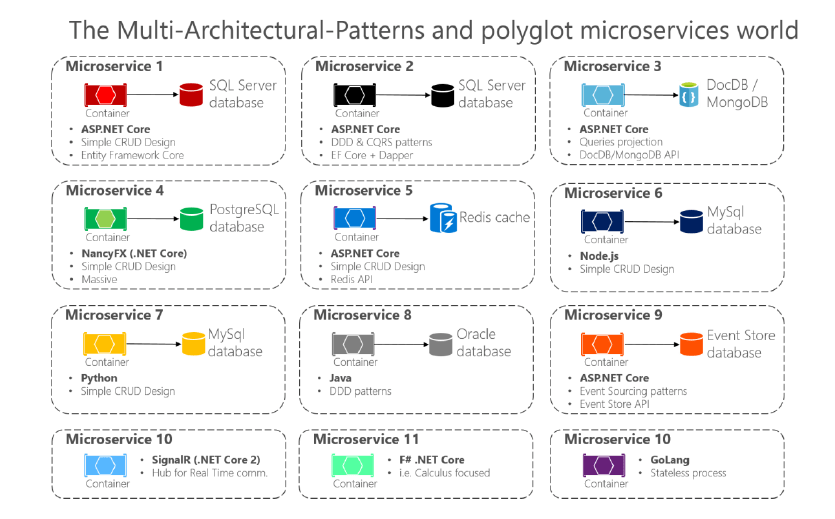
Going even further, different microservices often use different kinds of databases. Modern applications store and process diverse kinds of data, and a relational database is not always the best choice. For some use cases, a NoSQL database might have a more convenient data model and offer better performance and scalability than a SQL database. In other cases, a relational database is still the best approach. Therefore, microservices-based applications often use a mixture of SQL and NoSQL databases, which is sometimes called the polyglot persistence approach.
Communication between Microservices
There is a challenge in creating a solution that allows for efficient communications across the microservice system. Some ways of dealing with this is the use of an API Gateway. For simple data aggregation from multiple microservices that own different databases, the recommended approach is an aggregation microservice referred to as an API Gateway. However, you need to be careful about implementing this pattern, because it can be a choke point in your system, and it can violate the principle of microservice autonomy. Another solution for aggregating data from multiple microservices is the Materialized View pattern. In this approach, you generate, in advance (prepare denormalized data before the actual queries happen), a read-only table with the data that is owned by multiple microservices. This is also known as the CQRS (Command Query Responsibility Segregation) design pattern where the query and command functions are separated. Check Martin Fowler’s article in the References link below. For complex reports and queries that might not require real-time data, a common approach is to export your “hot data” (transactional data from the microservices) as “cold data” into large databases that are used only for reporting.

Most microservice-based scenarios demand availability and high scalability as opposed to strong consistency. Mission-critical applications must remain up and running, and developers can work around strong consistency by using techniques for working with weak or eventual consistency.
Sam Newman, a recognized promoter of microservices and author of the book Building Microservices, highlights that you should design your microservices based on the Bounded Context (BC) pattern (part of domain-driven design). Sometimes, a BC could be composed of several physical services, but not vice versa. A domain model with specific domain entities applies within a concrete BC or microservice. A BC delimits the applicability of a domain model and gives developer team members a clear and shared understanding of what must be cohesive and what can be developed independently. These are the same goals for microservices.
Another method of communication between microservices is to use an event bus. There are a couple of ways to implement this – Observable Pattern or Pub/Sub Pattern. In the Observer pattern, your primary object (known as the Observable) notifies other interested objects (known as Observers) with relevant information (events). The purpose of the Publish-Subscribe pattern is the same as the Observer pattern: you want to notify other services when certain events take place. But there is an important difference between the Observer and Pub/Sub patterns. In the observer pattern, the broadcast is performed directly from the observable to the observers, so they “know” each other. But when using a Pub/Sub pattern, there is a third component, called broker or message broker or event bus, which is known by both the publisher and subscriber. Therefore, when using the Pub/Sub pattern the publisher and the subscribers are precisely decoupled thanks to the mentioned event bus or message broker.
Note that when you publish integration events through a distributed messaging system like your event bus, you have the problem of atomically updating the original database and publishing an event (that is, either both operations complete or none of them).
Monolithic vs Microservices
The traditional monolithic application has a single solution with multiple modules embedded within it. The modules are tightly intertwined to each other as well as the infrastructure or global modules such as the datastore. The whole solution uses a single technology tech. Some disadvantages of this are:
- No restriction in size of application – as the application grows, so does it’s complexity. Deploying simple bug fixes require whole package deployment
- Large codebase
- Longer development time
- Longer / difficult deployment
- Inaccessible features
- Fixed technology stack
- Failure affects whole system
- Minor change requires full rebuild
- Single data source / database
Microservices addresses many of these flaws in it’s architecture. Some of the key benefits of microservice architecture:
- Shorter development time, groups can focus on specific services that are independent of other components of the system
- Reliable and faster deployment
- Enables frequent updates
- Decouples interdependent parts
- Security – as each microservice has its own datasource and data access, improves security
- Quick error response (focus on the specific part of that system)
- Highly scalable, improved performance
- Resilient – as a component goes down it doesnt impact the whole system; the failed component could be spun up quickly
Microservice Architecture follows the SOLID (programming) principle in that each component acts like class that is focused on a specific function. Each service has a single responsibility.
- Single Responsibility Principle
- Open closed Principle
- Liskov Substitution Principle
- Interface Segregation Principle
- Dependency Inversion Principle
By following these principles, each microservice becomes autonomous. This results in loose coupling and each service can evolve independent of other components. Each service can be running at different versions.
High Cohesion
Each microservice needs to have its single focus. Each business function or domain could have multiple microservices. For example, if were working with Accounts, we could have miroservices for Accounts Invoicing, Accounts Pay and Accounts Creation, etc. Each of these services could have its own dataservice and communicates with the other services through EDI documents over the network.
Autonomous
Each microservice should be loosely coupled in that they have minimal information to each other and communicate via network. We could have different teams working each of these microservices. There will be contracts put in place on how these teams communication between thee microservcics.
Domain Centric
Each microservice should represent a specific business domain. This reqiures developers to identify business domains and determine the level of granularity of the services for that domain.
Resilience
As more microservices are created, the complexity comes up with all the moving parts. It is important to design the error handler and failure detection. On failures, we may want to degrade or fall to default functionality for that service. Timeouts could also be used so that during internal communications between services if a transaction takes too long, we degrade or fallback to default quickly.
Centralized Monitoring
Have real-time monitoring for all the services. This include data points such as:
- response times
- timeouts
- exceptions / errors
- number of transaction
- average process time
- aggregated data
Also if running multiple microservices on a single host, we should have monitoring on that host for things like CPU, memory, etc.
Centralized Logging
Monitoring tracks numbers, such as how much is going on. Logging is tracking events, the actual actions that are going on. Logging should be done at startup through shutdown. Logging can be done for all data points listed in the monitoring, but more information about each of those events. This includes structured logging such as:
- Date Time
- Correlation ID
- Service Information
- Host information
- Level
- Information
- Error
- Debug
- Statistic
- Message / Event
- This should follow standardized format
Continuous Integration / Deployment
Automation tools are used in microservices to help manage the build and deployment of the services.
Synchronous Communication
For microservices to communicate synchronously with each other, we can use Remote Procedure Calls. Here the caller will make the call, wait for response, and then process the response. RPC acts like the endpoint is local, almost like calling another class library.
Also a traditional HTTP communication can be used across the network. These include communication like RESTful services. We should note that network latencies can affect the performance of the microservices.
Asynchronous Communication
Event based asynchronous communication is commonly used to decouple the client to service. A messaging queue can be used where a message broker will actually manage the communication. Here we follow a publisher / subscriber method where the client will simply subscribe to events it needs, as well as publish.
Virtualization
Microservices can run on physical machines or run all within a single host within virtual machines. This creates simplicity for not worrying about the hardware. Its also easy to clone the VM images. Some disadvantages of VM is that it takes time to startup/shutdown and requires maintenance for each of the images like a standalone server.
Containers
Similar to VMs containers also run on single host and can be easily cloned. They are lightweight compared to VM and reduce some of the maintenance overhead. They also perform faster with faster startup/shutdown.
Registration and Discovery
When several microservices are running, we need a way to find each one with an address. This can be done with a registry where each microservice will checkin and register itself. When the service goes down it will de-register itself.
API Gateway
An api gateway creates a central point to all the system’s services. It helps with perfromance, load balancing and caching. It also hides all the details of where the services are located making it easier to move them around. We can also control which services are exposed and which stay hidden. It can work as a registration like described above. Lastly it can help with security as it tracks all the communication happening throughout the system.
What happens when the application evolves and new microservices are introduced or existing microservices are updated? If your application has many microservices, handling so many endpoints from the client apps can be a nightmare. Since the client app would be coupled to those internal endpoints, evolving the microservices in the future can cause high impact for the client apps.
API Gateway Pattern
Also known as “backend for frontend” (BFF) because you build it while thinking about the needs of the client app. It helps manage relationships between clients and the backend microservices. It is an intermediate level or tier of indirection (Gateway) and very convenient for microservice-based applications. If you don’t have API Gateways, the client apps must send requests directly to the microservices and that raises problems, such as the following issues.
- Coupling: Without the API Gateway pattern, the client apps are coupled to the internal microservices. The client apps need to know how the multiple areas of the application are decomposed in microservices. When evolving and refactoring the internal microservices, those actions impact maintenance pretty badly because they cause breaking changes to the client apps due to the direct reference to the internal microservices from the client apps. Client apps need to be updated frecuently, making the solution harder to evolve.
- Too many round trips: A single page/screen in the client app might require several calls to multiple services. That can result in multiple network round trips between the client and the server, adding significant latency. Aggregation handled in an intermediate level could improve the performance and user experience for the client app.
- Security issues: Without a gateway, all the microservices must be exposed to the “external world”, making the attack surface larger than if you hide internal microservices not directly used by the client apps. The smaller the attack surface is, the more secure your application can be.
- Cross-cutting concerns: Each publicly published microservice must handle concerns such as authorization, SSL, etc. In many situations those concerns could be handled in a single tier so the internal microservices are simplified.
You need to be careful when implementing the API Gateway pattern. Usually it isn’t a good idea to have a single API Gateway aggregating all the internal microservices of your application. If it does, it acts as a monolithic aggregator or orchestrator and violates microservice autonomy by coupling all the microservices.

Some of the key benefits of using an API Gateway Pattern are:
- Reverse Proxy or Gateway Routing
- Requests Aggregation
- Cross-cutting concerns or gateway offloading – depending on the gateway’s capabilities some of the microservice features could be offloaded onto the gateway. For example the following items could be handled on the gateway:
- Authentication / Authorization
- Service discovery integration
- Response caching
- Retry policies, circuit breaker and QoS
- Rate limiting and throttling
- Load balancing
- Logging, Tracing, Correlation
- Headers, query strings and claims transformations
- IP whitelisting
General Purpose API Backend vs Backend For Frontend (BFF)
We could have a single general purpose API Gateway that handles all the different types of client requests. It sits in front of the backend and, at it’s worst-case, is like monolithic in that all traffic routes through it and therefore handles all the different business domains. To alleviate this, we could split the API Gateway to specific user experiences. For example, have an API Gateway catering to mobile users, another for web users, and another for everything else. This is the concept of Backend For Frontend (BFF).

- A single API gateway providing a single API for all clients.
- A single API gateway provides an API for each kind of client.
- A per-client API gateway providing each client with an API. This is the BFF pattern.
Addressing and Registry
Microservices need addressable names that make them independent from the infrastructure that they are running on. This implies that there is an interaction between how your service is deployed and how it is discovered, because there needs to be a service registry. In the same vein, when a computer fails, the registry service must be able to indicate where the service is now running. The service registry pattern is a key part of service discovery. The registry is a database containing the network locations of service instances. A service registry needs to be highly available and up to date. Clients could cache network locations obtained from the service registry. In some microservice deployment environments (called clusters) service discovery is built-in. For example, within an Azure Container Service environment, Kubernetes and DC/OS with Marathon can handle service instance registration and deregistration. These products fall under orchestration.
External vs Internal Design Patterns
When using microservice architecture, it is describing the external architecture. But within each microservice we could have an internal architecture where simplicity is the goal – for example using a simple CRUD based architecture. As a matter of fact – many different types of architectures could be implemented in a microservice system. Each service has its own architecture, as well as its own technology stack and even teams that development and maintain it.
Brownfield Microservices
This is where we are moving from a monolithic architecture to a microservices architecture. The process starts with identifying the seams or the separations between the business domains. We try to group the code to domains, much like domain driven design. There might be overlapping code, which may be applied to multiple domains. These code will require refactoring to depending on which parts go to what domain, which results in different services.
Once the application is divided into each of the domains, we can examine where the services will be created. Some domains may have multiple services. This breakout needs to prioritized, which may depend on various factors such as risk, technology or number of dependencies. This is an incremental approach so as the services are created, we need to make sure it still integrates with the original monolithic system.
Other things to consider are the communication strategies between the microservices, such as using an API Gateway. Also we will need to setup the centralized monitoring and logging. This should be done up front so that as other services are branched out it will be able to integrate into the monitor and logging.
Case Study – Netflix
Netflixes original architecture for their DVD data center consisted of a monolithic code base and database. This looked something like:

Developers would be deploying into a common code base and database. In this architecture scaling was done vertically only, where the hardware would be upgraded. Some of key problems with this approach and architecture were:
- Separation of Concerns
- Scalability
- Virtualization / Elasticity
Over time Netflix has decentralized their architecture and setup microservices based on different capabilities. The current architecture looks something like this:

Netflix created a system called Hystrix to manage faults in the system. It is a recovery system that detects errors and is able to quickly reroute connections to services that are available, as well as trying to fix those services that are in error. It also has reporting and monitoring to track the system in realtime.
Netflix also created a framework called FIT – Fault Injection Testing – which is a way to test the system when certain services are down. This can be done in a separate environment or even production. There are certain services that are considered critical, it must be available to 4 nines SLA (99.99%). The FIT framework will be able to test these services to ensure they are not down or able to quickly reroute or recover.
References
Martin Fowler
https://martinfowler.com/
Backends For Front Ends
https://samnewman.io/patterns/architectural/bff/
.NET Containerized Applications
https://www.microsoft.com/net/download/thank-you/microservices-architecture-ebook
CQRS
https://martinfowler.com/bliki/CQRS.html
Josh Evans – Netflix Director of Operations
QCon Session on Microservices at Netflix
Rag Dhiman
Microservices Architecture